01委员基本情况


02委员简介
涂志刚,武汉大学测绘遥感信息工程国家重点实验室研究员。主要研究领域为计算机视觉与机器学习,聚焦视频理解与人体动作行为的识别、重建。发表领域内权威期刊/会议学术论文近60篇,其中第一/通讯作者发表中科院一区SCI期刊+CCF A类会议论文20余篇(如IEEE TPAMI/TIP/TMM, CVPR/ICCV/IJCAI/ACM-MM)。主持湖北省杰出青年基金、教育部联合基金(青年人才类)、国家自然科学基金等科研项目。荣获2022湖北省自然科学二等奖(主持)、2020中国测绘学会测绘科技一等奖(参与)等多项省部级奖励。指导研究生荣获人工智能国际会议“最佳学生论文”1篇、国际计算机视觉顶会(ICCV2021)挑战赛2个赛道亚军。开发了视频人体行为智能识别与3D重建系统,并将其成功应用于“第七届世界军人运动会开闭幕式”等领域。担任多个国际期刊、专刊、会议的编委、领域主席。担任VALSE、CCF-CV专委会、CSIG青年工作委员会等学术组织执行委员、委员。
03委员亮点工作
1.“部位→个体→人群”体系化人体行为识别弱监督学习
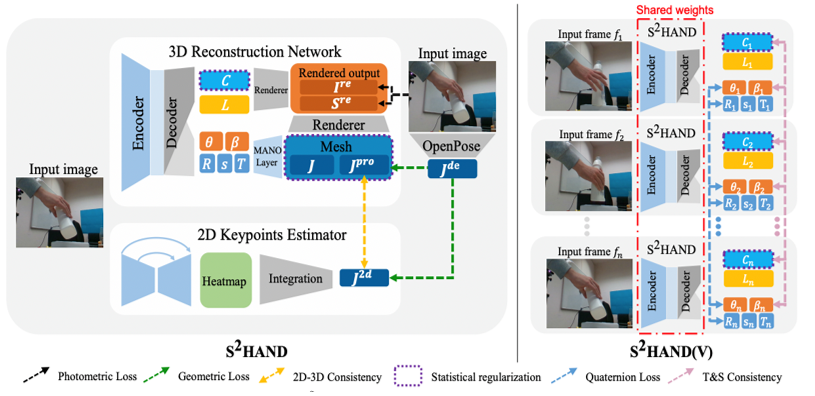
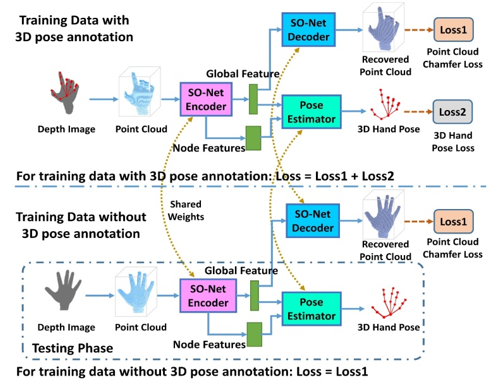
针对视频人体行为识别与重建模型对标注数据依赖性极高、模型泛化性不足的挑战,涂志刚团队展开了面向视频人体行为识别与重建的层次化弱监督学习研究,主要进行了2方面的尝试:1)提出了视频人体行为分析与识别的层次化弱监督模型构建体系。例如:人手重建,人体表征自监督学习。发展了首个从2D RGB图像重建高保真度3D人手的自监督模型。通过优化特征空间的高维人手表征和输出的人手姿态、形状、纹理等3D空间表征,实现了人手3D重建的自监督学习,精度达到了和之前全/弱监督方法相当的水平。近一步,提出了首个视频3D人手重建自监督模型(如图1-1所示),通过运动、纹理和形状一致性约束来获得更准确的手部姿势、更一致的形状和纹理。人手姿态估计,无标注人体表示增强半监督学习(如图1-2所示)。首次在手势估计领域引入点云自编码器,利用未标注数据构建自编码器实现无监督表征学习,结合少部分关键点标注训练高精度姿态估计半监督网络模型。人群异常检测,无监督学习。设计了基于2+1D卷积的自编码器架构,无监督学习视频目标的运动信息和外观信息,并构建了融合自编码器来学习目标运动特征和外观特征的关联性,实现了像素级的时空联合特征学习。2)提出了基于特征提取与特征评估的弱监督模型精度提升机制。针对半监督骨架动作识别,提出了骨骼-结点关联性特征提取方法。针对无监督人群异常事件检测,提出了重建误差与聚类距离联合的特征评估方法。
近年来,以第一/通讯作者身份发表TPAMI/TIP/PR 3篇,国际顶会CVPR/ICCV/ECCV 4篇。其中,ECCV2020关于无监督人群异常事件检测论文的谷歌学术引用超110次。2019年,基于“无监督人群异常行为检测技术”开发出“第七届世界军人运动会开闭幕式指挥调度系统”,荣获2020年中国测绘学会“测绘科技一等奖”。
2. 人体运动关联多视觉模态视频人体行为识别
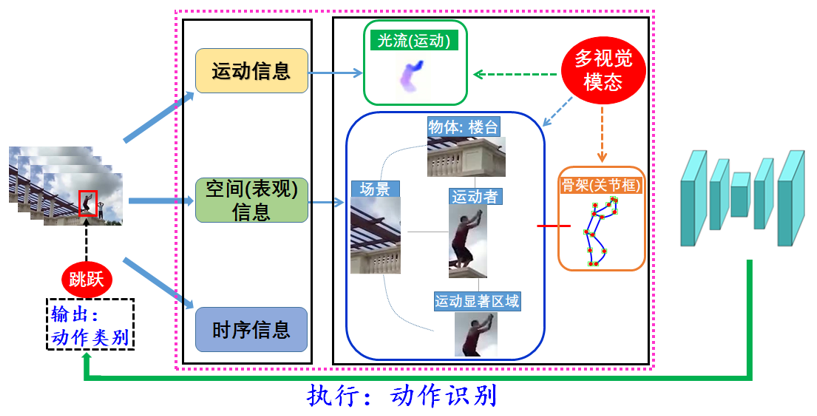
如何快速挖掘并计算具有互补特性的全局、局部、运动、细粒度等属性的多视觉模态,实现多模态特征融合表达是视频人体行为识别与重建领域的另一大挑战。启发于“多模态”并有别于“多模态”对多源数据的要求,涂志刚团队率先提出了“人体运动关联多视觉模态挖掘与特征融合表达的理论方法”(如图2所示),主要思想是“在单源视频数据,实现从单模单打独斗 → 多模多元协同的进化”。具体创新包括:1)启发性地提出了挖掘并计算与人体运动关联的多视觉模态思想,实现了精确、快速攫取服务于行为识别的丰富互补的多视觉模态。2)探索人体运动关联多视觉模态的相关性,提出了基于躯体结构的多视觉模态特征融合方法,增强了多视觉模态特征表达的有效性与可解释性。
近年来,以第一/通讯作者的身份发表中科院1区SCI论文7篇,1篇荣获ACAIT2020国际大会“最佳学生论文奖”并拓展至中国人工智能学会会刊 CAAI TIT;CCF A类会议论文3篇。谷歌学术搜索“Action Recognition Visual Multimodality”, 发表在IEEE TCSVT 2019的论文在5.21万个结果中排名第一。指导研究生荣获国际计算机视觉大会ICCV2021 ‒ MMVRAC视频人体行为识别挑战赛两个赛道的亚军。
3. 强抗干扰光流运动模态精确计算
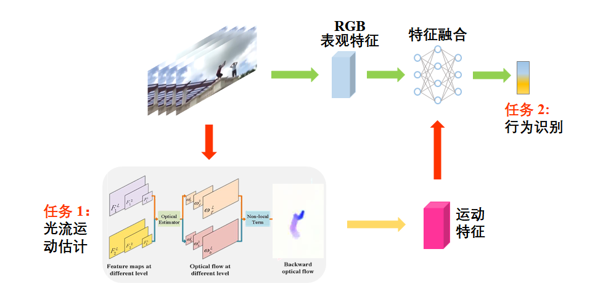
运动是人体行为的主要表现形式。如何高质量的获取、学习、利用运动信息模态,是解决人体行为多样性问题的关键。涂志刚团队构建了“强抗干扰光流运动模态精确计算方法体系”(如图3所示),主要思想是“宏观预处理 + 微观精细学习”。1)提出了强抗干扰视频光流运动模态计算理论,实现了复杂干扰因素综合处理。构建了以变分能量函数和深度神经网络为载体的新型光流计算方法,建立了较为完整的单一性、多样性干扰处理方法体系,具有普适性和精确性。2)提出了“人体行为驱动的运动信息计算”新机制,构建了多任务交互式深度学习模型,实现了光流模态估计与动作分类的交替优化,使获取的光流更侧重于描述人的行为变化及动作细节。
涂志刚团队10多年一直坚持视频光流运动估计的研究。以第一/通讯作者的身份发表SCI论文9篇。谷歌学术搜索“Optical Flow Survey”,2019年发表的光流综述论文在278万个结果中排名第二。
04委员专访

1. 请问您的研究领域包括哪些?最近进展如何?
近年来,团队的研究领域主要包括机器学习与视频理解,聚焦面向监控场景与虚拟场景的视频人体行为识别与3D人体重建。我们的团队立志于增强开发环境视频人体行为识别与虚拟场景人体重建的实用性。我们初步建立了体系化的人体行为识别与人体重建弱监督学习机制,发展了多视觉模态挖掘与特征融合表达方法体系。此外,我们紧跟视频人体行为理解的技术与应用发展趋势,将地面视频拓展至高空视频,将3D人体重建与可控内容生成结合,实现视频理解的广域覆盖。
2. 请向我们科普一下您研究领域相关的一项技术在应用中的具体体现。
我们团队开发的“大规模人群异常行为智能检测系统”成功应用于2019年“第七届世界军人运动会开闭幕式”。该系统实现了对开闭幕式现场各类人员(如观众、运动员、裁判、演出人员、服务人员、安保人员、嘉宾等),从手势,到个体动作,再到群体行为的多层次、全方位的实时检测、识别和预警。我们的成果被央视新闻和央视体育频道专题采访报道,得到了充分肯定,并为这次开闭幕式累计节省成本超亿元,产生了良好的经济与社会效益。
3. 对于希望进入图像图形领域的青年从业者,您希望他们加强那些方面的技能培养?
首先,要加强基础理论的学习。除了多阅读相关的顶会、顶刊论文外,还要多阅读一些与基础理论相关的文献,搞清楚图像图形处理的数学机理。其次,要加强理论与实践的结合,参与到解决“卡脖子”问题的工程项目中去,从实践中发现问题、解决问题。再者,要加强独立思考的能力,与不同交叉领域的学者专家交流沟通,寻找新颖的想法。