院士专家云集,共话前沿技术!
第十九届中国图象图形学学会青年科学家会议
将于12月28-31日在广州召开

由中国图象图形学学会青年工作委员会发起的“第十九届中国图象图形学学会青年科学家会议”将于2023年12月28-31日在中国广州召开。本次会议由中国图象图形学学会主办,琶洲实验室、华南理工大学、中山大学、中国图象图形学学会青年工作委员会承办。王耀南院士、谭铁牛院士、中山大学赖剑煌教授、华南理工大学徐向民副校长、许勇副校长、琶洲实验室常务副主任李远清教授、华南理工大学陈俊龙教授、北京大学林宙辰教授共同担任大会主席。
会议面向国际学术前沿与国家战略需求,聚焦最新前沿技术和热点领域,会议将设5个大会报告,27个主题分论坛,4个Tutorial,总计近150场高水平学术报告。本次会议邀请学术界和企业界专家与青年学者进行深度交流,促进图象图形领域“产学研”合作。
组织者:丁长兴(华南理工大学)舒祥波(南京理工大学)刘偲(北京航空航天大学)
已确定大会讲者

戴琼海
中国工程院院士

高文
中国工程院院士

周昆
计算机辅助设计与图形学
国家重点实验室主任

乔宇
上海人工智能实验室
主任助理、领军科学家
已确定论坛讲者(不分顺序)
大会讲者 |
戴海琼(中国工程院院士) |
高文(中国工程院院士) |
周昆(浙江大学,计算机辅助设计与图形学国家重点实验室主任) |
乔宇(上海人工智能实验室,主任助理、领军科学家) |
通用大模型学习与优化Tutorial |
刘静(中国科学院自动化研究所) 题目:多模态预训练模型的构建与应用 |
谢凌曦(华为技术有限公司) 题目:走向计算机视觉的通用人工智能:GPT和大语言模型带来的启发 |
东昱晓(清华大学计算机系) 题目:ChatGLM:预训练大模型实践与探索 |
NeRF神经辐射场与三维数字人Tutorial |
张鸿文(清华大学) 题目:稀疏视点下三维数字人体的动态重建与编辑 |
郑泽荣(杭州新畅元科技有限公司) 题目:基于神经辐射场的人体化身建模 |
王立祯(清华大学) 题目:基于神经辐射场的人脸生成与化身驱动 |
扩散模型与内容生成Tutorial |
邓志杰(上海交通大学) 题目:扩散概率模型基础及相关前沿进展 |
武宇(武汉大学) 题目:扩散模型进展与AIGC前沿应用 |
医学基准大模型Tutorial |
倪东(深圳大学) 题目:超声基础模型浅谈 |
张少霆(上海人工智能实验室) 题目:医疗场景中的基础模型-通才或专才 |
通用与视觉大模型论坛 |
邱锡鹏(复旦大学计算机学院) 题目:大模型的科学挑战 |
赵鑫(中国人民大学) 题目:大语言模型技术的研发与思考 |
王井东(百度) 题目:视觉大模型:实践和思考 |
王耀威(鹏城实验室) 题目:待定 |
代季峰(清华大学) 题目:开放任务下的视觉通用解码器网络 |
王鑫龙(北京智源人工智能研究院) 题目:从视觉到多模态基础模型 |
垂直领域大模型论坛 |
徐向民/靳战鹏(华南理工大学/未来技术学院) 题目:主动健康大模型探索 |
贺志阳(讯飞医疗科技股份有限公司) 题目:《医疗认知大模型技术进展与领域应用探索》 |
丁二锐(百度) 题目:文心·CV大模型闭环:半监督与多模态视角 |
丁凯(上海合合信息科技股份有限公司) 题目:文档大模型在工业落地中的挑战和探索 |
熊龙飞(珠海金山办公软件有限公司) 题目:办公领域大模型的技术路线和应用形态 |
遥感影像处理论坛 |
李春升(北京航空航天大学) 题目:星载SAR图像质量提升方法研究 |
李军(中国地质大学(武汉)) 题目:遥感图像时空融合技术的大尺度应用方法 |
徐丰(复旦大学) 题目:微波视觉与雷达智能目标识别 |
夏桂松(武汉大学) 题目:事件脉冲视觉感知理论、方法与应用 |
邹征夏(北京航空航天大学) 题目:物理驱动的遥感图像合成与解译 |
计算机图形学论坛 |
陈宝权(北京大学) 题目:AIGC与CG相融合的三维内容生成 |
刘利刚(中国科学技术大学) 题目:三维CAD实时渲染技术 |
王莉莉(北京航空航天大学) 题目:视觉感知模型驱动的高效凝视点绘制方法 |
刘烨斌(清华大学) 题目:基于神经辐射场域图像生成大模型的数字人技术 |
巫英才(浙江大学) 题目:大数据可视化分析技术与应用 |
虚拟数字人论坛 |
刘永进(清华大学) 题目:虚拟数字人的情感计算与人机共情研究 |
周晓巍(浙江大学) 题目:基于神经表达的体积视频技术 |
于涛(清华大学) 题目:创造真实的虚拟人 |
梁小丹(中山大学) 题目:可控数字人生成及编辑 |
张举勇(中国科学技术大学) 题目:基于单目视频的高保真数字人建模与驱动 |
三维视觉论坛 |
许威威(浙江大学) 题目:三维内容的神经网络表达构建技术探讨 |
欧阳万里(上海人工智能实验室) 题目:大模型时代下的三维视觉 |
谢晋(南京理工大学计算机学院) 题目:复杂场景下三维点云视觉感知与理解 |
李坤(天津大学) 题目:低成本、高效率、高质量、自然合理的人体重建与生成 |
戴玉超(西北工业大学) 题目:动态场景三维重建:从显式到隐式再到生成 |
无人系统论坛 |
王鹏(西北工业大学) 题目:无人移动平台自主进化学习方法与应用 |
吴琦(澳大利亚阿德莱德大学) 题目:基于语言指令的无人车/机导航系统 |
高性能AI计算与AIOT论坛 |
李超(上海交通大学) 题目:面向边缘多模态计算的软硬协同优化探索 |
庄博涵(Monash University) 题目:预训练大模型的高效微调和部署 |
唐卓(湖南大学) 题目:区域型算力网络关键技术探讨 |
龚湛(浪潮信息) 题目:算力驱动智能驾驶进化 |
神经网络架构论坛 |
黄高(清华大学) 题目:高效视觉Transformer的结构设计与训练方法(待定) |
胡瀚(微软亚洲研究院) 题目:统一计算机视觉识别任务的DETR网络结构 |
徐畅(悉尼大学) 题目:探索神经网络架构的表示与理解 |
叶齐祥(中国科学院大学) 题目:视觉表征模型结构设计-从剧不特征耦合的Conformer到全预训练模型iTPN |
丁霄汉(腾讯AI Lab) 题目:“结构重参数化”的理念,发展脉络与代表性工作 |
多模态计算论坛 |
卢志武(中国人民大学高瓴人工智能学院) 题目:多模态通用生成模型的基本框架与最新进展 |
彭宇新(北京大学) 题目:多维感知驱动的AIGC |
宋井宽(电子科技大学) 题目:多媒体紧致表征与分析 |
徐常胜(中国科学院自动化研究所) 题目:视频理解中的关系学习研究 |
徐航(华为诺亚方舟实验室) 题目:文本导向的多模态生成的一些探索和实践 |
俞俊(杭州电子科技大学) 题目:基于Transformer框架的多模态学习 |
生成式人工智能论坛 |
朱军(清华大学) 题目:基于扩散模型的离线强化学习 |
林倞(中山大学 计算机学院) 题目:可控及个性化跨模态图像创作 |
刘红敏(北京科技大学) 题目:扩散模型在视频感知任务中的应用(暂定) |
鲍秉坤(南京邮电大学) 题目:跨模态图像生成 |
左旺孟(哈尔滨工业大学) 题目:文本引导的可控图像与视频生成 |
刘子纬(新加坡南洋理工大学) 题目:大模型时代下的多模态AIGC |
人工智能伦理与治理论坛 |
段伟文(中国社科院) 题目:生成式人工智能将如何改变我们的学习和教育 |
王迎春(上海人工智能实验室) 题目:大模型创新变革与治理挑战 |
本力(香港中文大学(深圳)高等金融研究院) 题目:知识产权视角下的人工智能伦理治理 |
程林(柏林自由大学) 题目:规避林格里奇困境:当代机器人叙事中的机器人性别与伦理反转 |
曹建峰(腾讯研究院) 题目:生成式人工智能的伦理治理思考 |
智能视频分析论坛 |
查正军(中国科学技术大学) 题目:真实场景低质视觉增强与分析 |
胡卫明(中国科学院自动化研究所) 题目:网络内容跨模态语义理解与安全事件推理 |
林巍峣(上海交通大学) 题目:面向视频及语义数据的联合处理与编码 |
吴祖煊(复旦大学) 题目:基于Transformer的视频内容理解 |
王亚立(中国科学院深圳先进技术研究院) 题目:复杂视频表征与理解 |
目标检测与跟踪论坛 |
卢湖川(大连理工大学) 题目:高性能视觉跟踪 |
黄迪(北京航空航天大学计算机学院) 题目:面向无人机航拍图像的目标检测 |
钟必能(广西师范大学) 题目:智能视觉理解及其相关应用 |
李晶晶(电子科技大学) 题目:领域自适应学习 |
王乐(西安交通大学人工智能与机器人研究所) 题目:更通用的多目标跟踪:从多类型到极端场景跟踪 |
郑锋(南方科技大学) 题目:多模态融合的视频跟踪与分割 |
自动驾驶论坛 |
张兆翔(中国科学院自动化研究所) 题目:基于点云数据的驾驶场景感知 |
李长升(北京理工大学) 题目:自动驾驶中动态障碍物轨迹预测与自车决策规划 |
薛建儒(西安交通大学) 题目:自主智能运动系统研究发展与展望 |
刘偲(北京航天航空大学) 题目:开放视觉感知 |
丁文超(复旦大学) 题目:自动驾驶场景理解与预测决策技术 |
仉尚航(北京大学) 题目:迈向开放世界自动驾驶泛化感知 |
以人为中心的视觉计算论坛 |
山世光(中国科学院计算技术研究所) 题目:基于视觉的情感和心理感知技术 |
杨易(浙江大学) 题目:多重知识驱动的人体跟踪、重建与生成 |
郑伟诗(中山大学) 题目:连续一致行人重识别 |
王琦(西北工业大学) 题目:面向真实场景的人群计数研究及其应用 |
涂志刚(武汉大学) 题目:视频人体动作行为识别与捕捉 |
丁长兴(华南理工大学) 题目:跨模态行人重识别 |
脑科学与类脑智能论坛 |
田永鸿(北京大学博雅特聘教授) 题目:大规模类脑神经网络理论与方法 |
邬霞(北京师范大学) 题目:受脑机制启发的强化学习 |
金晶(华东理工大学) 题目:脑机接口范式设计、算法优化及应用研究 |
陈霸东(西安交通大学) 题目:人机混合增强智能 |
徐鹏(电子科技大学) 题目:面向智能交互的个体行为解码技术 |
何晖光(中国科学院自动化研究所) 题目:细粒度情绪神经信息编解码 |
俞祝良(华南理工大学) 题目:稀疏贝叶斯学习在端到脑电图解码中的应用 |
图像分割论坛 |
魏云超(北京交通大学) 题目:Visual Segmentation for Open World |
沈为(上海交通大学) 题目:依“聚”识别 |
张鼎文(西北工业大学) 题目:面向数据受限场景的图像目标分割技术 |
王妍(华东师范大学) 题目:超限医学图像分析:技术与应用 |
雷印杰(四川大学) 题目:面向真实场景分割的智能视觉理解 |
可信人工智能论坛 |
吴飞(浙江大学计算机学院) 题目:大模型基座赋能:由通到专的实践和思考 |
张新鹏(复旦大学) 题目:从信息隐藏到功能隐藏 |
苏航(清华大学) 题目:大模型时代的安全人工智能方法 |
周建涛(澳门大学) 题目:面向社交网络的多媒体信息安全和取证 |
王奕森(北京大学) 题目:Time to Rethink Adversarial Examples |
工业视觉论坛 |
待定讲者 题目: |
吴宗泽 题目: |
刘敏(湖南大学) 题目:基于视觉感知的表面缺陷检测方法及系统 |
刘宏(北京大学) 题目:面向复杂场景的人体运动视觉感知 |
杨敬钰(天津大学) 题目:面向工业视觉的图像重建与分析 |
国雍(华为) 题目:鲁棒注意力机制的探索及应用 |
机器人与具身智能论坛 |
卢策吾(上海交通大学) 题目:具身智能-感知(P),想象(I),执行(E)PIE方案与具身大模型探索 |
黄凯(中山大学) 题目:Lateral Flexion of a Compliant Spine Improves Motor Performance in a Bio-Inspired Mouse Robot基于柔性脊柱的仿生老鼠机器人运动控制 |
王鹤(北京大学) 题目:具身智能的Sim2Real途径 |
赵斌(西北工业大学) 题目:人工智能软银件一体化探索 |
杨鑫(大连理工大学) 题目:类脑具身感知 |
丛杨(华南理工大学) 题目:机器人视觉感知,自主技能泛化及思考 |
生物医学影像论坛 |
刘剑楠(上海交通大学医学院附属第九人民医院) 题目:口腔肿瘤智能诊疗 |
马建华(西安交通大学) 题目:医学CT重建中的滤波反投影算法:从经典到前沿 |
屈小波(厦门大学) 题目:物理智能磁共振成像 |
涂圣贤(上海交通大学) 题目:深度学习在冠心病诊疗中的应用进展 |
杨萌(北京协和医院) 题目:光声成像技术研发及临床应用 |
青年学者服务论坛1 |
指导专家:陈松灿(南京航空航天大学) |
指导专家:左旺孟(哈尔滨工业大学) |
指导专家:肖斌(重庆邮电大学) |
指导专家:王震(西北工业大学) |
指导专家:李泽超(南京理工大学) |
青年学者服务论坛2 |
指导专家:赖剑煌(中山大学) |
指导专家:操晓春(中山大学) |
指导专家:李哲涛(暨南大学) |
指导专家:刘敏(湖南大学) |
指导专家:蔡瑞初(广东工业大学) |
优博论坛 |
胡建芳(中山大学) 题目:跨模态时域视频内容理解与分析 |
刘鑫辰(京东探索研究院) 题目:大规模自然场景步态识别初探 |
黄鑫(南阳师范学院) 题目:基于知识迁移的跨媒体检索与推理方法研究 |
张平平(大连理工大学人工智能学院) 题目:多模态感知的全天候行人重识别 |
李佳男(北京理工大学) 题目:真实环境下的三维场景感知与理解 |
女青年科学家论坛 |
黄惠(深圳大学) 题目:Decoding Data Dimensions:Urban Insights,3D Understanding,and Visual Emotions |
杨欣(华中科技大学) 题目:基于视觉的深度估计与定位 |
阚美娜(中国科学院计算技术研究所) 题目:多源领域泛化与自适应 |
贲睍烨(山东大学) 题目:微表情识别:读脸读心 |
徐雪妙(华南理工大学) 题目:基于知识引导的场景智能理解鹤生成技术 |
陈俊颖(华南理工大学) 题目:高效自监督训练方法及模型轻量化探索 |
青托沙龙 |
樊彬(北京科技大学) 题目:面向鲁棒视觉定位的图像特征学习 |
王雁刚(东南大学) 题目:动力学约束的人体运动捕捉与重建 |
余旻婧(天津大学智能与计算学部) 题目:情绪控制的语音驱动数字人表情动画生成 |
丛润民(山东大学) 题目:水下环境智能感知与应用 |
唐彦嵩(清华大学深圳国际研究生院) 题目:细粒度视频理解与生成 |
研究生论坛 |
张军平(复旦大学) 题目:高质量读研 |
林宙辰(北京大学) 题目:如何写好论文 |
会议基本信息
2023年12月28-31日(星期四-星期日)
会议地点:
广州花都融创施柏阁大观酒店(广东省广州市花都区凤凰北路75号)
论坛主题
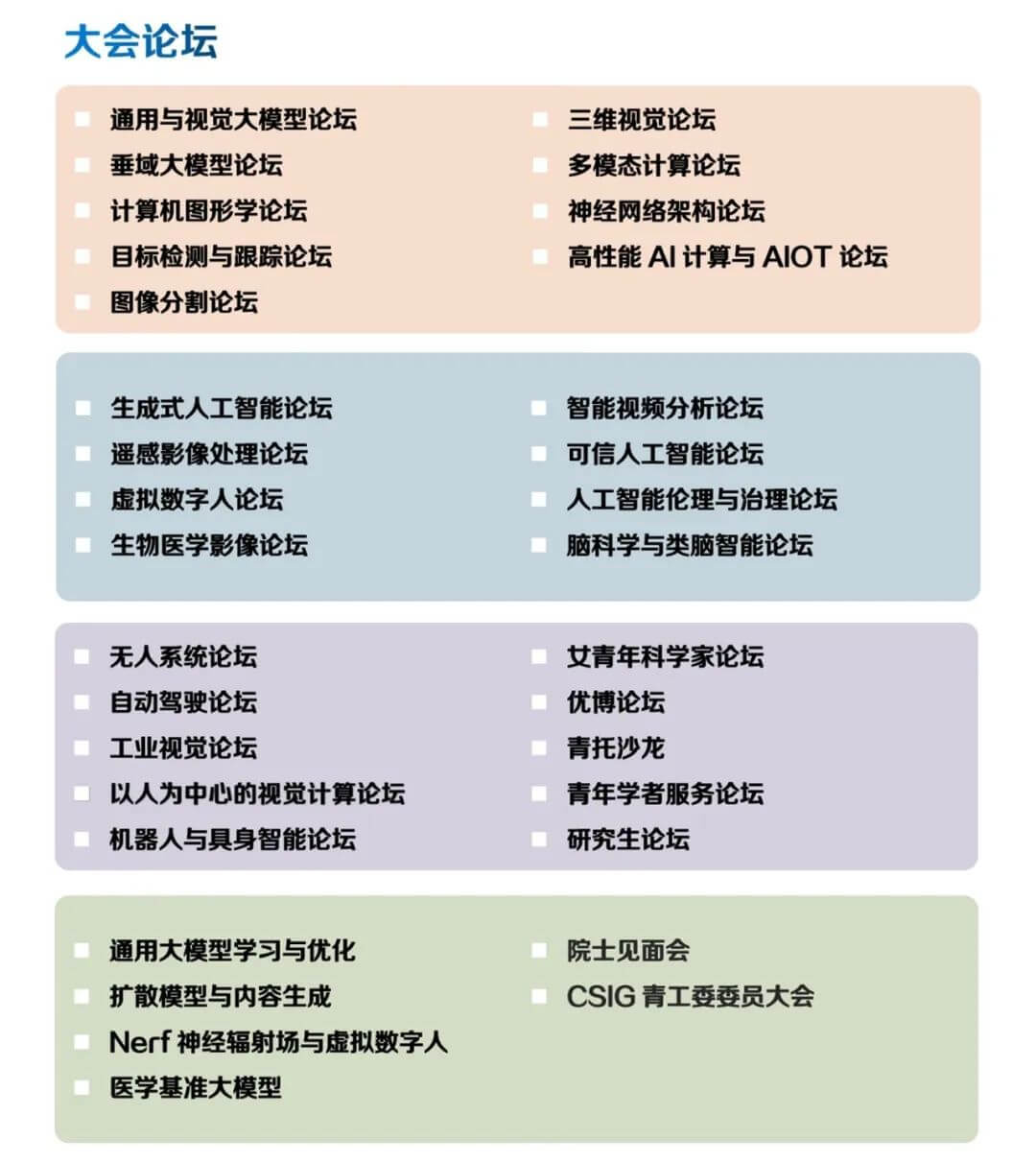
会议组织架构
大会主席:
王耀南院士谭铁牛院士
赖剑煌(中山大学)徐向民(华南理工大学)许勇(华南理工大学)
李远清(琶洲实验室)陈俊龙(华南理工大学)林宙辰(北京大学)
程序委员会主席:
谭明奎(华南理工大学)金连文(华南理工大学)聂礼强(哈尔滨工业大学)
白翔(华中科技大学)贾伟(合肥工业大学)丛润民(山东大学)
姬艳丽(电子科技大学)
组织委员会主席:
邹月娴(北京大学)俞祝良(华南理工大学)郑伟诗(中山大学)
元辉(山东大学)杨欣(华中科技大学)蔡毅(华南理工大学)
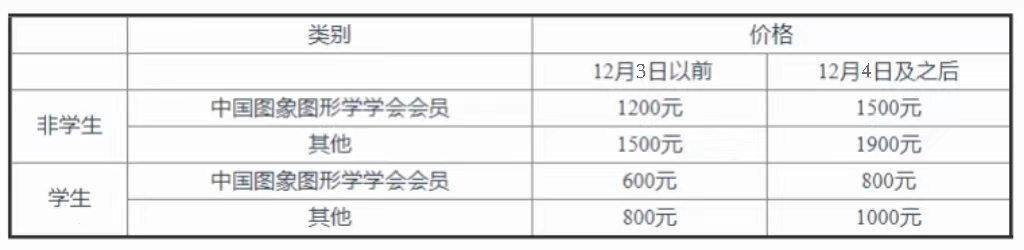
注册及缴费标准
会议采取线上注册的形式进行报名,中国图象图形学学会会员和非会员均可注册参会,学生享有近半价优惠。12月3日以前报名者可享受早鸟价。
收费标准:
注册请登录会议注册链接:
http://youth.csig.org.cn/CSIG2023/Registration.html
或扫描注册二维码进行注册:

更多会议的详细信息请访问:
http://youth.csig.org.cn/CSIG2023/index.html
或扫描会议官网二维码:
联系方式:
秘书处邮箱:secretariat_csig@163.com
墙报征集
为给青年学者提供更多展示自己学术成果的机会,本次大会设立了墙报展示环节,拟征集2021年以来机器学习、图象图形学以及相关交叉应用领域最新研究200篇于会场进行展示。同时大会组委会设立了“最佳论文奖”和“优秀论文奖”以奖励青年学者所做出的卓越研究。
投稿方式:请于2023年11月20日前在线填写报名表单,并根据官网提供的Poster格式与样例进行制作,连同论文一起发送至csig_poster@163.com。
扫描二维码填写墙报报名表单:

官网链接查看评奖规则以及墙报格式规定与样例:
http://youth.csig.org.cn/CSIG2023/Poster.html
联系方式:
王扬:15864526351
QQ群:677858473
